

撞上数据墙?OpenAI模型提升速度放缓 着手调整开发策略

财联社消息,高质量数据不够用,拖累AI模型改进速度——OpenAI这位AI领头羊又遇到了难题。
一些测试过Orion的OpenAI员工发现,虽然Orion的性能超过了OpenAI现有的所有模型,但其性能质量提升程度远远小于从GPT-3到GPT-4的飞跃。这意味着,随着高质量数据趋于有限,AI模型的改进速度可能会放缓。
不仅如此,Orion的训练中涉及来自旧模型(例如GPT-4与一些推理模型)的AI生成数据,这可能导致其重现旧模型的一些行为。
为此,OpenAI成立了一个“基础”团队,以在高质量新数据供应减少的情况下,研究能让AI模型保持改进的新方法。据悉,公司计划基于AI合成数据训练Orion,并在后期训练中对模型作出更多改进。
目前,OpenAI正在推进Orion的安全测试,计划于明年年初发布这一模型,其可能会打破“GPT-X”的命名惯例,以反映模型开发的变化。
值得注意的是,OpenAI在今年收购了Chat.com域名,该域名已重定向至OpenAI的AI驱动聊天机器人ChatGPT。
▌“撞上数据墙”
早在2020年,OpenAI就曾在一篇论文中提出Scaling law定律,意指大模型的最终性能主要与计算量、模型参数量和训练数据量三者的大小相关,而与模型的具体结构(层数/深度/宽度)基本无关。换言之,仅仅增加模型规模和训练数据,就能显著提升人工智能能力,而无需取得根本性的算法突破。
AI界许多公司都一度将Scaling Law奉为圭臬,但如今,也有越来越多的质疑声出现。
Meta AI人工智能研究院(FAIR)研究员及高级经理田渊栋指出,“我画过一张图,一开始数据量越大,模型性能表现越好,但模型离人类越近就越难获得新的数据,模型就越来越难以改进,最后总会有些corner case(边角案例,即无法想到的或不常见的案例)解决不了,这是data driven(数据驱动)最大的问题。”
非营利研究机构Epoch AI在今年7月更新的一篇论文中指出,未来数年内,(原始)数据增长的速度将难以支撑AI大模型扩展发展的速度,在2026-2032年之间的某个时间点,数据存量将耗尽。
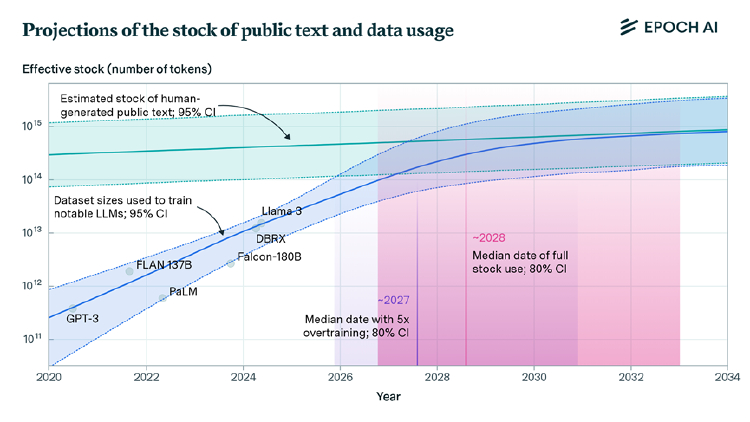
实际上,OpenAI已不是第一次遭遇“数据资源不足”的问题。此前已有媒体报道指出,在训练GPT-5时,OpenAI因文本数据不足,正在考虑使用YouTube公开视频转录出的文本。
如今OpenAI再度碰上数据资源难题,甚至因此影响到了新模型进展。“但这代表‘天塌了,’”The Information这篇文章的作者之一Amir Efrati指出,OpenAI正在作出调整,或许将有新的Scaling Law取代旧Scaling Law。
值得一提的,当地时间11月9日,OpenAI安全系统团队负责人翁荔(Lilian Weng)宣布将离开已经工作了近7年的OpenAI。她公开分享了发给团队的离职信,但其中并未言明具体离职原因及未来职业去向,仅表示“是时候重新出发,探索新的领域了”。
原标题:撞上数据墙?OpenAI模型提升速度放缓 着手调整开发策略
