科学大院微信公号消息,2016年,AlphaGo 战胜围棋冠军李世石之后,人工智能开始火了。各行各业都在探索人工智能的应用。尤其是在人脸识别领域,人工智能的应用飞速发展。

深圳交警在全国率先正式启用“刷脸”执法 (图片来源:Leiphone.com)

2018年5 月 19 日,哈里王子的婚礼直播中采用人脸识别技术。这项技术将由亚马逊云服务(Amazon Web Services)提供,可以一秒识别 600 位宾客的身份。(图片来源:Sky News)
最近每隔一两个月就有新闻报导在歌神张学友的演唱会上有逃犯被抓,因此歌神获得了“逃犯克星”的美誉,其背后的功臣就是人工智能加持的人脸识别系统。既然人工智能这么厉害,那么它是不是能帮助我们识别浩瀚星空中的星系呢?
此音叉不会演奏音乐 但可让星系排排坐
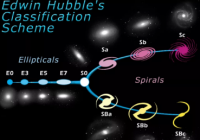
在天文学领域,也有一项研究和人脸识别类似,就是星系形态的识别。天文学家通过星系的外观长相对星系进行分类,其中最有名的一种分类方法是由著名的天文学家Edwin Hubble (哈勃)于1926年提出的哈勃序列。
他按照结构从简单到复杂把星系排序:排在最左边的是球对称的椭圆星系,椭率越大的漩涡星系被排列在越右边。椭圆星系序列的最右端是透镜星系(因为其形状像透镜)。拥有旋涡结构的星系被划分到再右边的两个序列中:旋涡星系和带棒状结构的棒旋星系。因为这个分类结果很像音叉,所以又称为“哈勃音叉”(见图1)。

哈勃音叉图 (图片来源:维基百科)
天文学家为什么需要根据形态对星系分类呢?因为星系的形态往往反映了其形成和演化的历史,这包括星系之间合并的历史、星系周围的环境、星系内部的扰动、中心黑洞的活动以及恒星形成的历史等等。因此在研究星系的形成与演化方面,基于星系形态进行的分类为天文学家们提供了非常有价值的信息。

不同历史时期的“哈勃音叉图”(从左到右为:现在、40亿年前和110亿年前,图片来源:NASA, ESA, M. Kornmesser)
几十年来,该领域的研究都是依赖天文学家人眼识别对星系形态进行分类,这样产生的研究样本数量都不是很大,例如最初的“哈勃音叉图”只包含大约400个星系。当现代大型巡天项目比如斯隆数字巡天(SDSS)开始运行之后,上百万的星系需要进行分类,这样的工作量对于个人或者小型团队来说显然无法完成。于是天文学家们想到了不同的办法来处理海量的星系图像。
星系动物园:热心的群众不止会吃瓜
2007年,天体物理学家Kevin Schawinski希望从统计上比较椭圆星系和旋涡星系的恒星形成率。为此他需要给斯隆数字巡天数据库里的上百万颗星系形态分类。他一周连续工作七天每天工作12个小时,才识别出五万颗星系。
一个周五的晚上,Schawinski和他的好友兼同事Chris Lintott在酒吧喝酒的时候聊起了这项研究工作,受 NASA 一个项目的启发,他们有了一个想法:把这些星系图像发布到一个网站,让那些感兴趣的爱好者帮忙识别星系,做成一个科研方面的众包项目(见图2)。在接下来的几天,在几个热心程序员的帮助下,Lintott 和 Schawinski做了一个网站,并于7月14日上线,这个项目被命名为“星系动物园”(Galaxy Zoo)。
果然是人多力量大,上线不到24小时,星系识别的速度就达到了每小时7万多个,超过了Schawinski一周的工作量。甚至由于访问量过大,使得斯隆数字巡天项目的服务器宕机了。网友的热情大大超出了两位创始人的预期。在Lintott发表的第一篇关于Galaxy Zoo的学术论文中,已经有10万人次进行了4千万次分类,而且志愿者们的分类准确度和专业的天文学家相比,误差在10%以内,即使只把其中最为可靠的分类结果挑选出来组成样本,数量也比之前最大的样本高出一个数量级。
无论是从科学产出还是从社会影响力方面,星系动物园成为了最为成功的公众科学项目。截止到2017年,总共有超过一亿两千五百万个星系被分类,基于这些分类结果,有超过60篇学术论文发表。荷兰的女教师Hanny van Arkel甚至发现了一种新的奇特的天体,后来还以她的名字命名为“Hanny's Voorwerp”。就如Schawinski所说,“我们成功创建了世界上最强大的星系识别超级计算机,它是由登录我们网站的人们组合而成,这个超级大脑在识别星系方面达到的速度和精度令人难以置信。”
在“星系动物园”项目获得巨大的成功之后,他们相继发起了一些类似的针对其他巡天结果的星系形态识别项目,比如“星系动物园2”、“星系动物园:Hubble”和“星系动物园:CANDELS ”。但是志愿者的增加速度并没有赶上数据增加的速度,而且在未来,当更大的巡天项目(比如LSST,EUCLID等)开始运行以后,将有数以亿计的星系需要分类,即使依赖更多的志愿者显然也无法在短时间内完成。

星系动物园:志愿者们通过回答上述问题来完成对星系形态的分类 (图片来源于Willett等2013年论文“Galaxy Zoo 2: detailed morphological classifications for 304122 galaxies from the Sloan Digital Sky Survey”)
机器识别错误率高?科学家们出新招
大家自然会想到,为什么不让计算机来做这些海量的“看起来很简单”的工作。其实问题就在于这样的工作对于计算机来说并不简单,自动识别图像一直是计算机领域一个难题。人脑在图像模式识别方面的能力是远胜于计算机的,但是我们也可以让计算机程序学习这种本领,机器学习就是实现人工智能的一种方法,现在各种人工智能使用的方法主要就是机器学习。这种方法利用程序从数据中自动学习隐藏的规律,并用来预测未知的数据或者做出决策。
天文学家们也一直尝试使用各种机器学习方法自动识别星系的形态,但最初的尝试并不顺利。早在1995年,天文学家们就用神经网络、决策树等机器学习方法对星系形态进行分类,尽管这些早期的尝试只应用于几百个星系的小样本,但是正确率也只有80%。而且这些研究大都只是把星系分为三类:椭圆星系、漩涡星系和其它。如果再进行更复杂的分类,正确率将大幅下降。比如2004年的一项研究发现,仅仅把三种类别增加到五种,就使得正确率大约从90%下降到50%。
2013年底的时候,“星系动物园”项目组发起了一项奖金高达一万六千美元的挑战赛,挑战赛的目标就是希望机器学习算法利用“星系动物园2”项目的数据集能够达到人眼识别星系类别的水平。最后,比利时根特大学的博士生Sander Dieleman获得了第一名。其实他原本的研究方向和天文完全不相关,是关于利用机器学习算法进行音乐信息的提取和分类。他利用卷积神经网络算法进行星系形态分类,取得了和人眼识别几乎完全一致的结果。

人脸识别时每一层神经网络“学习”的特征。
卷积神经网络是近些年在图像识别领域日渐主流的算法。尤其是在人脸识别领域,该方法可以让机器学习达到甚至超过人类的水平。所谓“卷积”是一种数学运算,这种运算应用到图像上,相当于为图像加上某一种滤镜。这种滤镜称为“滤波器”或“特征探测器”,它可以提取图像的某些特征,产生的结果叫做特征图(feature map)。
算法由许多层组成,每一层都可以使用多个滤波器以探测图像的多个特征,特征的复杂性随着层数的增加而增加,即形成一个“网络”。比如在图像分类中,一个卷积神经网络的第一层学会了探测像素中的边缘,然后第二层利用这些边缘再去探测简单的形状,更高层再利用简单的形状去探测更高级的特征,比如人脸形状;最终得到此图像属于不同类别的概率。
在传统机器学习中,需要人为地根据经验和专业知识设计这些“滤镜”,这一步需要耗费大量的时间和人力。卷积神经网络的好处是可以从数据中自动“学习”需要提取的特征。但是它需要海量的标准的数据样本进行“学习”,这个数据样本叫做训练集,而且越复杂的算法需要越大的训练数据集。对于星系形态分类来说,“星系动物园”项目中成千上万的人对星系图像进行标注,产生的结果自然就可以就成为了各种卷积神经网络算法的训练和测试数据集,这个庞大的标准的数据集对于机器学习的效果至关重要。
在这个挑战赛中,Dieleman和合作者选取了大约6万张“星系动物园2”项目中标记好的星系图像作为训练数据集,他们通过改变图像中心、镜像对称以及旋转来产生新的图像,扩大训练数据集。其中旋转图像能够让神经网络学习星系的旋转对称性。这一步非常重要,因为星系形态分类不应该依赖观察图像的方向,而获取那些恒定不变的特征是非常关键的。
然后他们利用这个数据集训练卷积神经网络,像人类一样回答图2中一系列的问题。他们的网络有7层,每一层都能够为了更高阶的特征而有效过滤数据。之后,他们利用训练好的神经网络测试另外大约8万张星系图像,进而将程序识别的结果和人眼识别所标记的结果比较。最终Dieleman的算法获得的分类结果几乎和人眼一致,而且个人电脑就足够提供算法所需要的计算能力。
训练集可以“移花接木”吗?
前面提到过机器学习非常依赖训练集的质量,而众包产生的人类识别结果依然是最好的训练集。机器学习存在一个问题:训练好的算法只适用于特定的数据集,当你提供不同的数据集时,算法并不会自动做出调整。这样在特定数据集有效的算法可能在另一个数据集失效。由于不同巡天项目的望远镜分辨率、灵敏度和点源扩展函数等都存在差异,不同的巡天项目相当于不同的数据集。
因此人们希望回答下面的问题:在现在的算法水平下,是不是每个巡天项目都需要建立一个数量庞大的训练集?有没有可能利用A巡天的训练集“学习”得到的算法应用于B巡天,这样又可以大大减少人类的工作量。假如不能完全应用,那么从A巡天训练集“学习”的知识有多少可以应用到B巡天?需要做出多少改进才能完全应用于B巡天?
Dominguez Sanchez和她的合作者们在2018年尝试解答上面的问题。他们将原本用于斯隆数字巡天第七次公开数据的算法应用于暗能量巡天(Dark Energy Survey)的星系图像。当利用斯隆数字巡天训练的算法直接应用于暗能量巡天的星系图像时,识别精度勉强可以(>80%),当利用暗能量巡天的已经识别的样本继续训练算法,即使采用很小的样本(比如500个已经识别的星系图像)也能够显著提高算法对暗能量巡天的星系图像的识别精度(>95%)。这项研究工作告诉我们卷积神经网络的“学习”成果具有可迁移性,而且应用到新的巡天项目的星系图像时,所需要增加的新的训练集可能只是原本的十分之一。
除了光学波段,天文学家也把卷积神经网络应用于射电波段的星系图像。最近南非的天文学家 Aniyan 和澳大利亚天文学家Chen Wu 分别根据不同的分类方法利用卷积神经网络对射电星系进行分类,这些先驱性的研究将为以后的平方公里阵(Square Kilometer Array)射电望远镜做准备。平方公里阵射电望远镜是计划建在南非和澳大利亚的全球性合作项目,我们中国也是主要成员国之一。当它开始运行之后,也将有数以亿计的射电星系需要被证认和分类,届时我们也只能依靠机器学习来完成这项繁重的工作。
未来,依靠卷积神经网络将星系们归类,人类将在认识宇宙的路上又迈出一大步!
作者单位:中国科学院上海天文台
原标题:当AI仰望星空的时候,它在想什么?
【免责声明】上游新闻客户端未标有“来源:上游新闻-重庆晨报”或“上游新闻LOGO、水印的文字、图片、音频视频等稿件均为转载稿。如转载稿涉及版权等问题,请与上游新闻联系。